Determinants of education:Heckman, Stixrud, and Urzua (2006), Almlund et al. (2011), Björklund and Salvanes (2011), Ichino, Rustichini, and Zanella (2022)
Genes and environment in education: Rustichini et al. (2023)
UK Household Longitudinal Study (2009-)
Working sample: 22 881 individuals
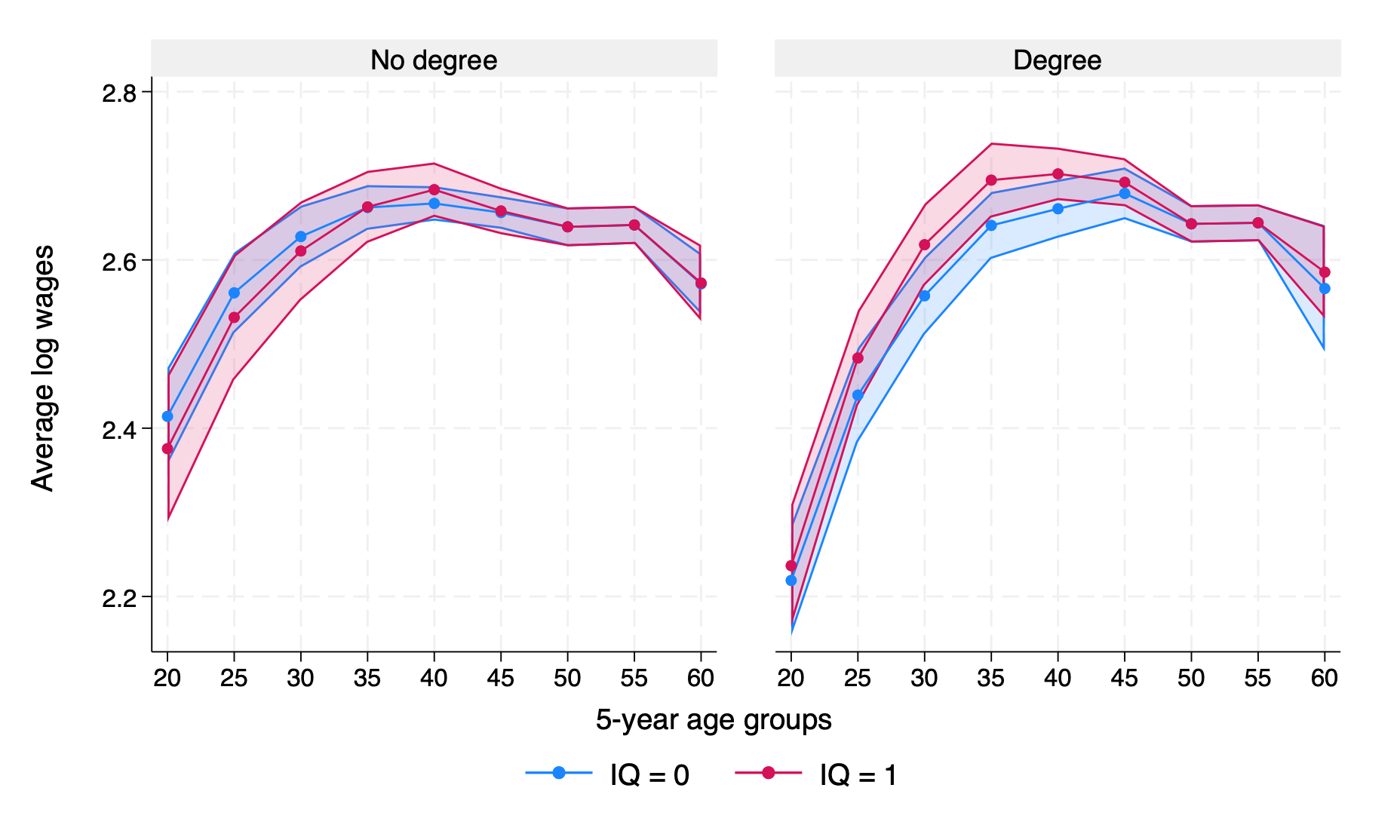
college: ever had HE degree as highest qualification
predicted discounted present value of earnings
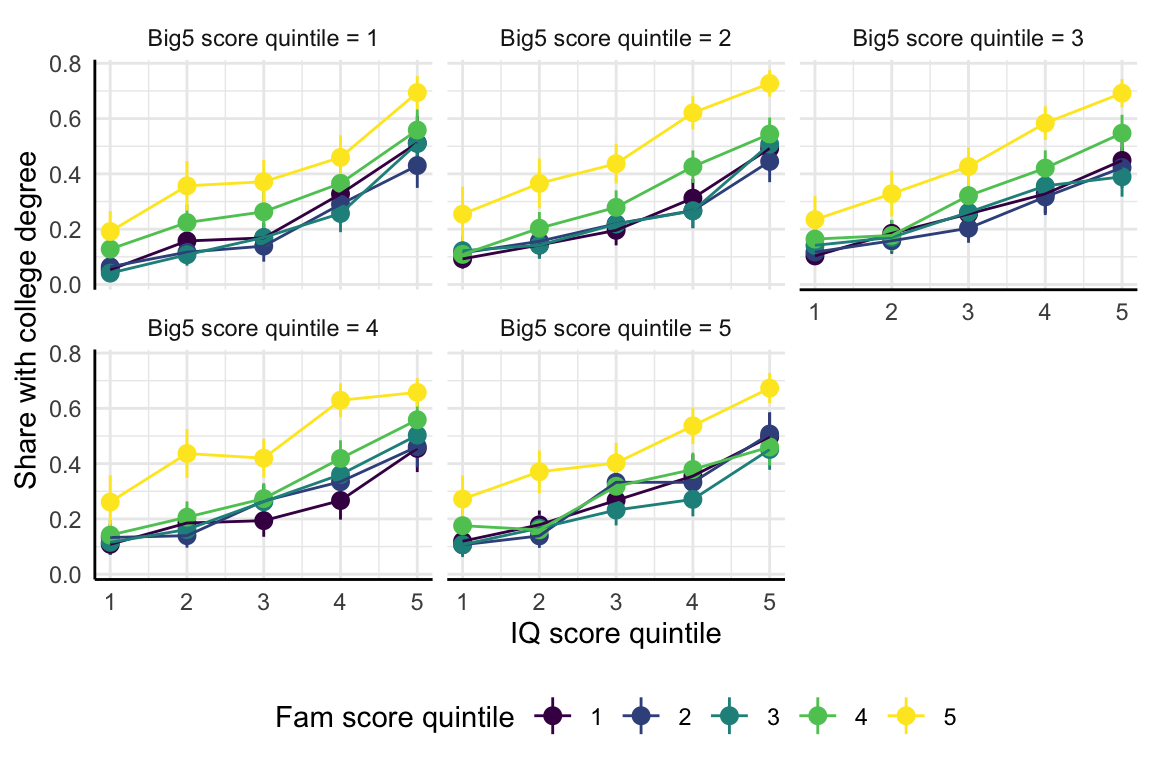
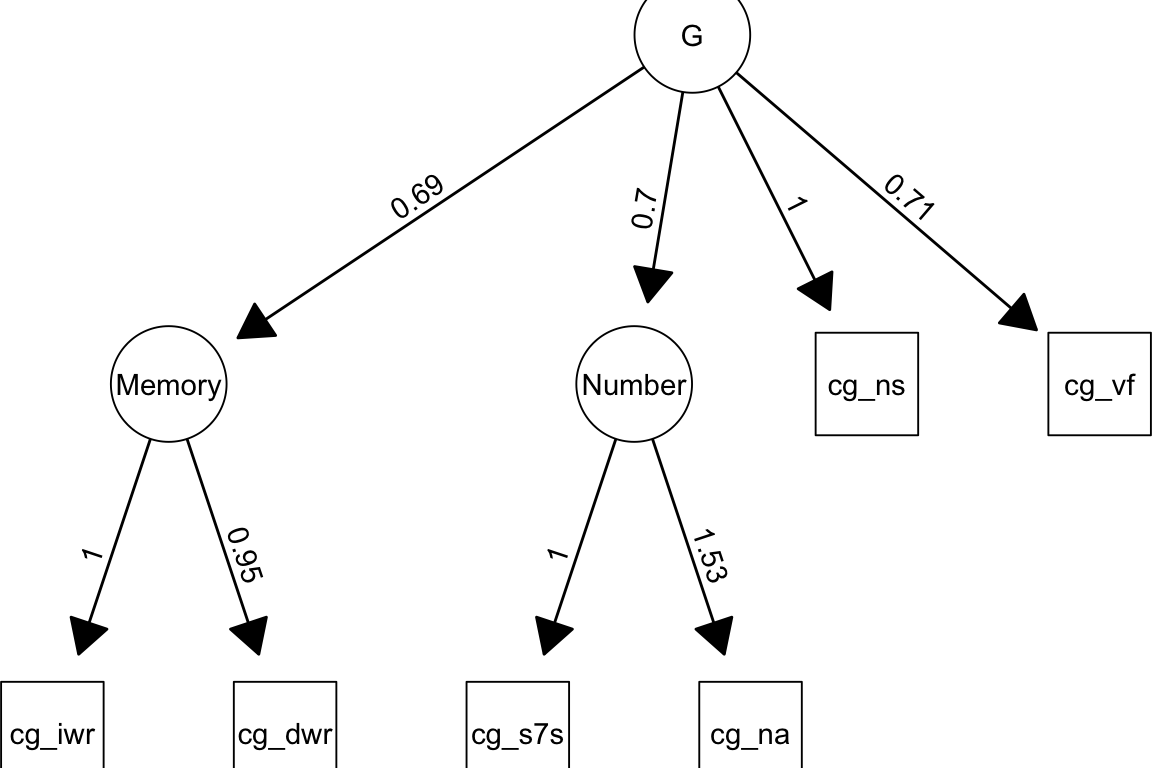
cognitive test scores , Big 5 personality scores
parental background: education and employment status
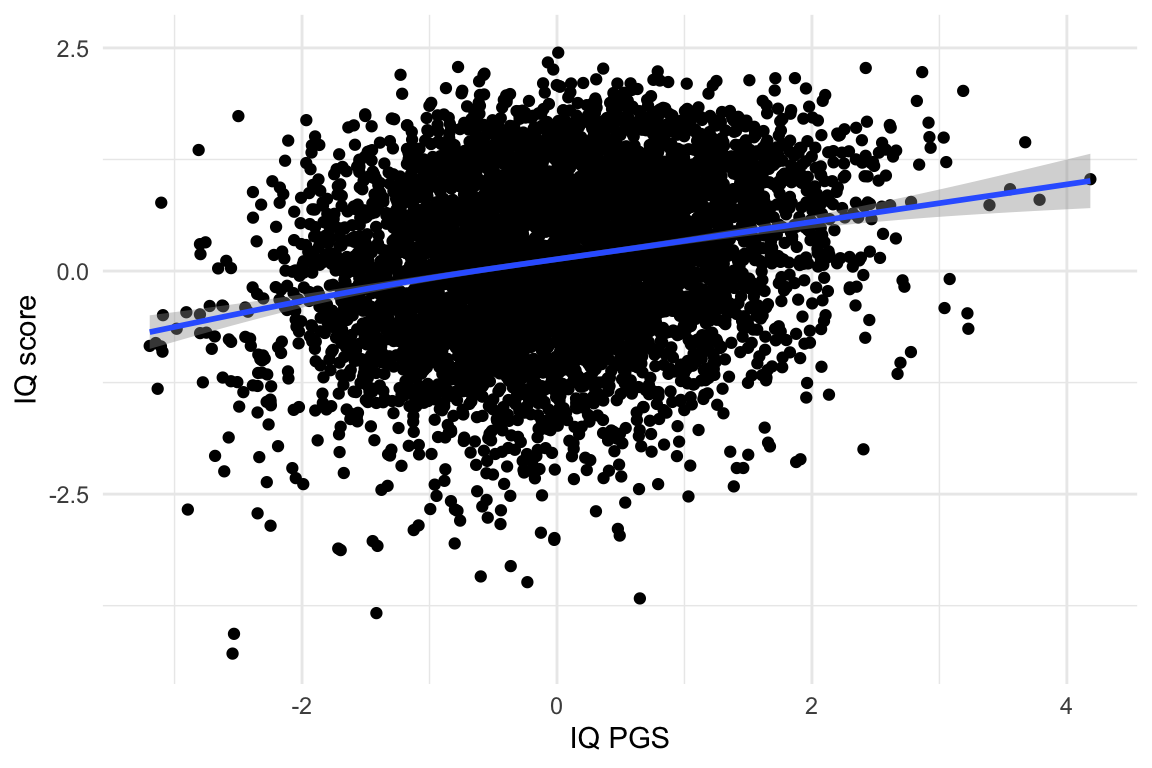
mdac %>%ggplot(aes(x = pgs_std_cobs_hm3p, y = g_score_std)) +geom_point() +geom_smooth() +labs(x ='IQ PGS', y ='IQ score') +theme_minimal()
`geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'
Warning: Removed 978 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 978 rows containing missing values or values outside the scale range
(`geom_point()`).
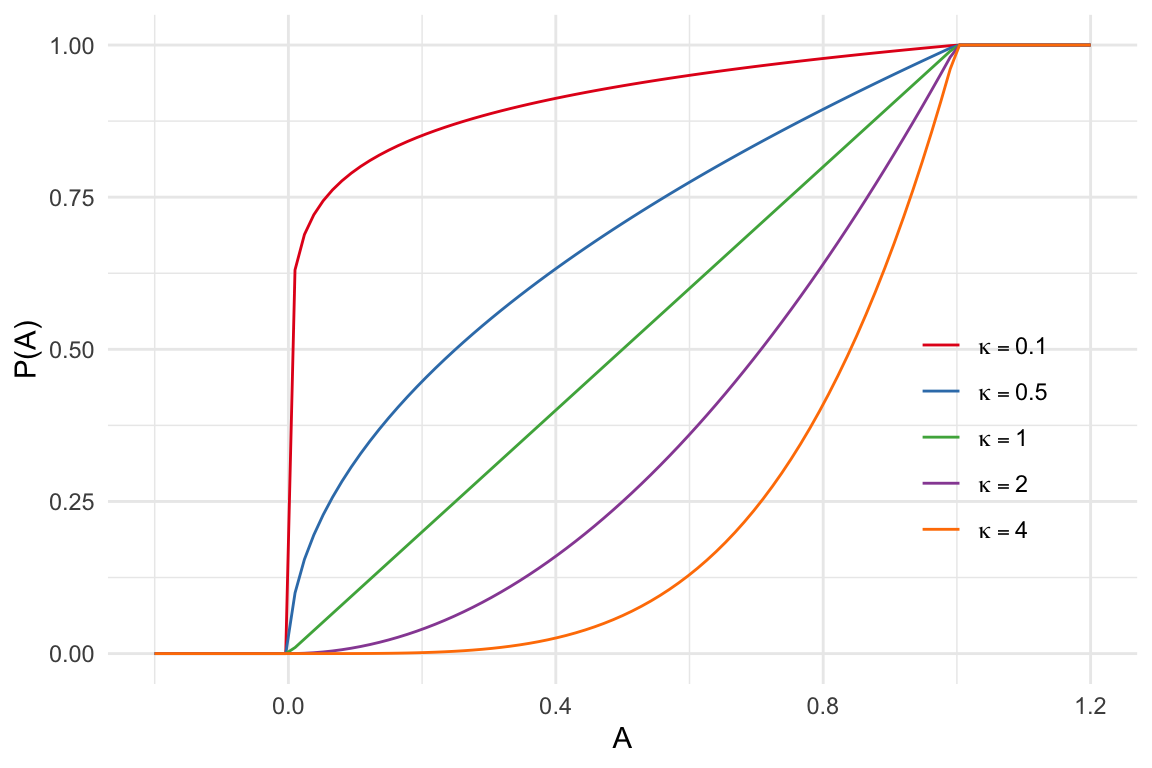
Proposition (continuously differentiable)
Redefine the effort choice problem as where .
The set of endogenous probabilities is the set of multivalued functions that are decreasing, closed valued, with , for some .
For any function which is continuously differentiable strictly decreasing in the interval , with , , there exists a continuously differentiable function such that for all , .
Proposition proof (continuously differentiable)
Note that for , so we may take the boundary condition
Consider the ordinary differential equation
We now define the function as the solution of . The function satisfies the differential equation, which is the first order necessary and sufficient conditions for optimal effort choice problem, namely . Thus, our claim follows.
Warning: A numeric `legend.position` argument in `theme()` was deprecated in ggplot2
3.5.0.
ℹ Please use the `legend.position.inside` argument of `theme()` instead.
Heckman, James, Jora Stixrud, and Sergio Urzua. 2006. “The Effects of Cognitive and Noncognitive Abilities on Labor Market Outcomes and Social Behavior.”Journal of Labor Economics 24 (3): 411–82.
Rustichini, Aldo, William G. Iacono, James J. Lee, and Matt McGue. 2023. “Educational Attainment and Intergenerational Mobility: A Polygenic Score Analysis.”Journal of Political Economy 131 (10): 2724–79. https://doi.org/10.1086/724860.
Savage, Jeanne E., Philip R. Jansen, Sven Stringer, Kyoko Watanabe, Julien Bryois, Christiaan A. de Leeuw, Mats Nagel, et al. 2018. “Genome-Wide Association Meta-Analysis in 269,867 Individuals Identifies New Genetic and Functional Links to Intelligence.”Nature Genetics 50 (7): 912–19. https://doi.org/10.1038/s41588-018-0152-6.